@InProceedings{stitch_ope,
title={{STITCH}-{OPE}: Trajectory Stitching with Guided Diffusion for Off-Policy Evaluation},
author={Hossein Goli and Michael Gimelfarb and Nathan Samuel de Lara and Haruki Nishimura and Masha Itkina and Florian Shkurti},
booktitle={Advances in Neural Information Processing Systems},
year={2025}}
STITCH-OPE Workflow
The STITCH-OPE framework operates through a systematic workflow that combines conditional diffusion modeling with guided trajectory generation:
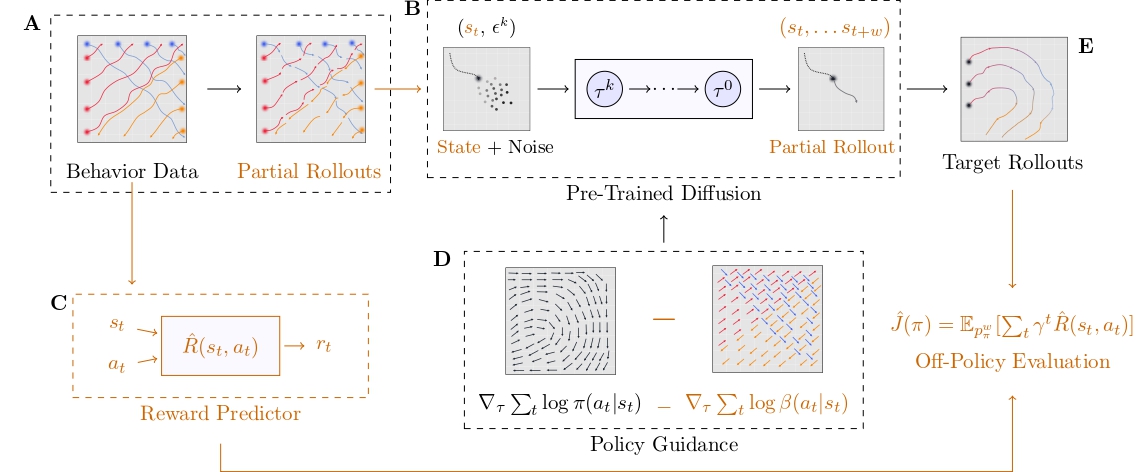
Workflow Explanation
- Data Preprocessing: Behavior data is segmented into partial trajectories of length w, enabling more flexible trajectory composition during guided diffusion.
- Conditional Diffusion Training: A diffusion model is trained on sub-trajectories conditioned on initial states, learning to generate dynamically feasible behavior patterns while maintaining broader coverage of the behavior dataset.
- Guided Trajectory Generation: During inference, the diffusion model generates target policy trajectories using dual guidance:
- Positive guidance from the target policy score function
- Negative guidance from the behavior policy score function to prevent over-regularization

Illustration of positive and negative guidance in the diffusion process
- Trajectory Stitching: Generated sub-trajectories are seamlessly stitched together end-to-end to form complete long-horizon trajectories, minimizing compounding errors while preserving compositionality.
- Off-Policy Evaluation: The stitched trajectories are evaluated using an empirical reward function to estimate the target policy's expected return, providing robust OPE estimates even with significant distribution shift.